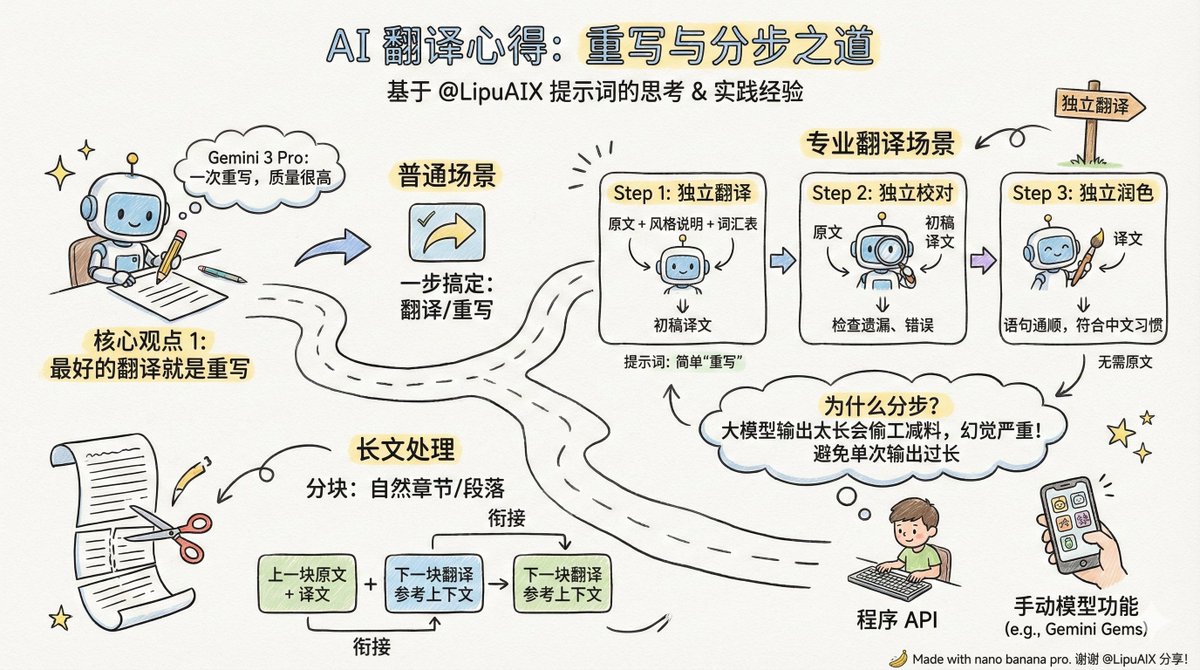
AI 翻译的本质:从词对词映射到语义重构
AI 翻译的本质是通过大语言模型(LLM)将源语言的语义映射至目标语言

它已从早期的词对词映射,演变为基于上下文的语义重构。到 2026 年,AI 翻译的竞争焦点将从单纯的“准确率”转移到对特定领域知识的对齐能力以及对文学语感的模拟能力。
必须认清 AI 翻译的统计学本质。无论模型参数规模如何,它并不真正“理解”文化深意,而是计算在当前语境下哪个词出现的概率最高。这种机制使其在处理标准化文档时效率极高,但在面对高创造力或严谨学术定义的文本时,仍存在“幻觉”风险——即生成一个看起来专业但实际错误的译词。
如何构建高精度翻译工作流
要将 LLM 转化为高精度翻译工具,目前最有效的路径是:提示词工程(Prompt Engineering)+ 检索增强生成(RAG)+ 人工审校(Human-in-the-loop)。
1. 高精度 Prompt 的构建逻辑
构建高精度翻译 Prompt 需包含角色定义、领域上下文、术语约束和输出格式
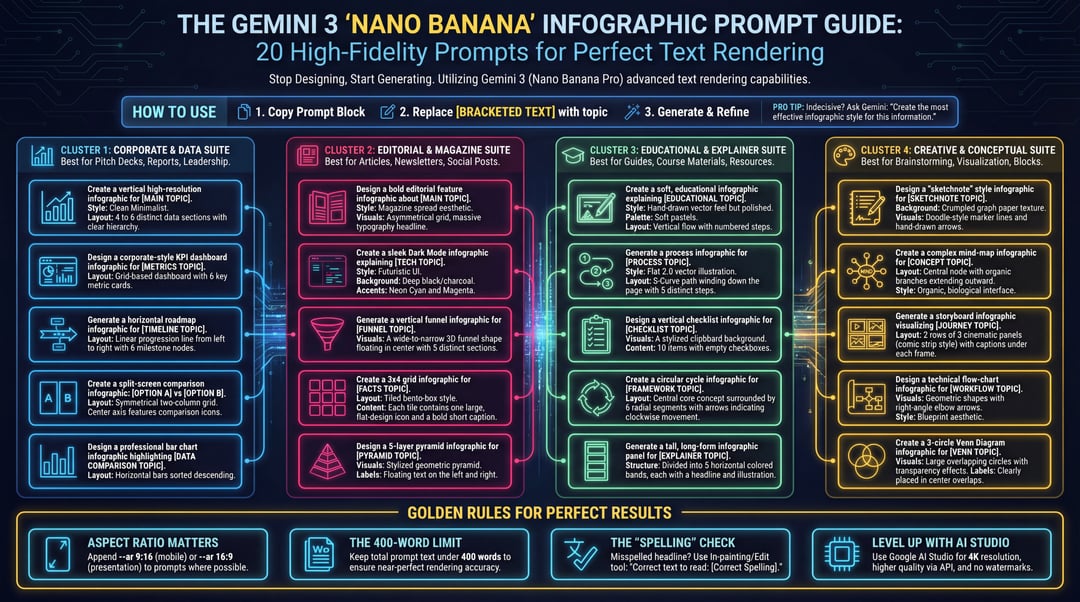
1. 定义角色: 例如“你是一位拥有 20 年经验的量子物理专业翻译...”。
2. 注入上下文: 明确文本用途(如:发表在 Nature 杂志)。
3. 设定约束: 严禁增减原意,多义词需列出候选并说明理由。
4. Few-Shot 引导: 提供 3-5 组正确翻译示例以对齐语言偏好。
若译文仍有偏差,可要求 AI 先将原文拆解为语义块,分析深层含义后再翻译,以降低机翻感。
2. 大规模文档处理的技术要点
处理大规模专业 PDF 文档时,建议调用 API 配合集成工具。在模型选择上,应根据需求匹配能力:
| 模型类型 | 推荐模型 | 适用场景 |
|---|---|---|
| 轻量级模型 | Gemini-2-Flash | 快速初稿、降低成本、大意浏览 |
| 重量级模型 | Claude 3.5 / GPT-4o | 复杂逻辑、文学性文本、精翻 |
操作时,分段长度(Chunk Size)是关键
建议设置在 1000-2000 Token 之间。分段过长会导致模型丢失文首上下文,过短则会破坏句子完整性导致译文断层。若遇到 API 频率限制,可开启“自动重试”并将间隔设为 5 秒。导出时务必选择双语对照格式以方便核对。
人机协作的闭环优化
完全依赖 AI 翻译在 2026 年依然具有风险,尤其是出版物或法律文件。成熟的协作闭环应为:AI 初翻 $\rightarrow$ 领域专家核对术语 $\rightarrow$ 文学编辑润色语感
在术语对齐阶段,发现错误后不要仅手动修改单处,而应将正确译法加入 RAG 知识库或 Prompt 术语表并重新运行该章节,确保全书术语一致。
在润色阶段,编辑的作用是剔除生硬句子,赋予文本生命力。此时编辑的角色已从翻译员转变为“语言雕刻师”。
AI 翻译的适用边界与局限
AI 翻译并非万能,以下三种场景建议谨慎使用
- 强文化隐喻的文学作品: 方言或特定历史时期的俚语,AI 往往只能给出字面意思,无法传递意境。
- 高法律责任条款: 在涉及巨额交易的合同中,“可能”与“应当”的区别至关重要,人类法务的签署确认比 AI 结果更可靠。
- 小众语种: 缺乏大规模语料库的濒危语言,AI 翻译易出现逻辑混乱甚至虚构。
Q: 面对大量外文资料,如何兼顾成本与质量?
建议采取分层处理法:先用 Gemini-2-Flash 快速浏览大意,针对关键段落切换至 Claude 或 GPT-4 等高级模型精翻,最后由专业人士核对核心术语。这是目前成本最低且质量最高的最优解。
Q: AI 会取代翻译员吗?
AI 并没有取代翻译员,而是取代了简单的文字搬运工作。未来的竞争力在于能否驾驭模型,将 AI 作为生产力插件,而将判断力留在最后一步。